A review of the limitations of financial failure prediction research
ABSTRACT
The objective of this paper is to critically evaluate the main weaknesses associated with the limitations of financial failure prediction research studies. For more than 80 years, researchers have unsuccessfully studied ways to create a general theory of financial failure, which is useful for prediction. In this paper, we review the main boundaries of failure prediction research through a critical evaluation of previous papers and our own approach from the research experience. Our findings corroborate that these studies suffer from a lack of theoretical and dynamic research, an unclear definition of failure, deficiencies with the quality of financial statement data and a shortfall in the diagnostic analyses of failure. The most relevant implications for future research in this area are also outlined. This is the first study to analyse in deep the caveats of financial failure prediction studies, a crucial topic nowadays due to the hints of an economic crisis caused by the Covid-19 pandemic.
Keywords: Financial distress; Financial failure; Bankruptcy; Prediction; Limitations.
JEL classification: G33; M41; C19; C59.
Revisión de las limitaciones de la investigación sobre predicción de quiebras financieras
RESUMEN
El objetivo de este artículo es evaluar críticamente los principales puntos débiles asociados a las limitaciones de los estudios de investigación sobre predicción de quiebras financieras. Durante más de 80 años, los investigadores han estudiado sin éxito la forma de crear una teoría general del fracaso financiero que sea útil para la predicción. En este artículo, revisamos los principales límites de la investigación sobre predicción de quiebras mediante una evaluación crítica de trabajos anteriores y nuestro propio enfoque a partir de la experiencia investigadora. Nuestras conclusiones corroboran que estos estudios adolecen de una falta de investigación teórica y dinámica, una definición poco clara del fracaso, deficiencias con la calidad de los datos de los estados financieros y un déficit en los análisis de diagnóstico del fracaso. También se esbozan las implicaciones más relevantes para futuras investigaciones en este ámbito. Se trata del primer estudio que analiza en profundidad las salvedades de los estudios de predicción de la quiebra financiera, un tema crucial en la actualidad debido a los atisbos de crisis económica provocados por la pandemia del Covid-19
Palabras clave: Dificultades financieras; Quiebra financiera; Bancarrota; Predicción; Limitaciones.
Códigos JEL: G33; M41; C19; C59.
1. Introduction
Financial failure prediction has been extensively studied in the last few decades, since the pioneer studies of Beaver (1966) and Altman (1968). Indeed, as of August 1st, 2021, there are 3,929 manuscripts in the ISI Web of Knowledge -the most well-known academic database- with the keywords "failure prediction" in the search by topic. Interestingly, more than 79% have been published after the 2007 global financial crisis. The 2007 global financial crisis led many researchers to find ways to reduce financial failure risks by developing new models to predict financial distress situations (Alaka et al., 2018). Wu (2010, p. 2371) justified the interest in this research avenue stating that although failure prediction models currently achieve a collective average accuracy of more than 85%, few persons can bear a risk of less than 100% accuracy. Failed businesses generate huge economic losses not only for the firm's shareholders and creditors, but they also burden nations with immense social and economic costs (Alaka et al., 2018; Xu & Zhang, 2009).
Despite the vast number of papers on financial failure prediction, we contribute to the literature by exploring new insights into the limitations of this research area. This paper aims to identify the main theoretical and practical limitations of bankruptcy prediction literature and develop guidelines for future research. We examine the main boundaries of financial failure prediction research through a critical review and evaluation of limitations from prior literature. Our study is the first one to provide a classification of the limitations, assessed from both theoretical and empirical approaches.
In regards to the theoretical approach, financial failure prediction has been addressed from several perspectives. In organizational research, a number of different theoretical foundations has been used to describe firm failures (Kücher et al., 2015; Kücher et al., 2018), such as neoclassical economic theory (White, 1989), agency and prospect theory (D'Aveni, 1989), the theory of population ecology (Fuertes-Callén et al., 2022; Hannan & Freeman, 1977), catastrophe theory (Scapens et al., 1981), resource-based theory (Thornhill & Amit, 2003), and deterministic and voluntaristic theory, or an integration of both (Amankwah-Amoah, 2016; Carter & Van Auken, 2006; Kücher et al., 2018; Mellahi & Wilkinson, 2004). However, regardless of the popularity of the topic in different research domains, there is still no comprehensive theory to explain how firms fail and how their failure should be conceptualized. Prior research agrees on the need to achieve a unique theory to explain financial failure (Dias & Teixeira, 2017; Lensberg et al., 2006; Lukason, 2016; Makropoulos et al., 2020; among others) because the lack of theoretical scientific analysis of the failure phenomenon weakens the conceptualization of the event of interest (failure), the understanding of failure behaviour process, the formulation of new failure prediction models, the choice of variables for these models, the role of financial and non-financial variables, the justification of the functional form between the variables and a logical understanding of the meaning of results (Alaka et al., 2018, Balcaen & Ooghe, 2006; Dimitras et al., 1996; Kirkos, 2015; Lensberg et al., 2006).
The connection between the lack of theoretical foundations of financial failure research and the empirical limitations is shown in Figure 1.
Figure 1. The framework of the limitations on failure prediction research
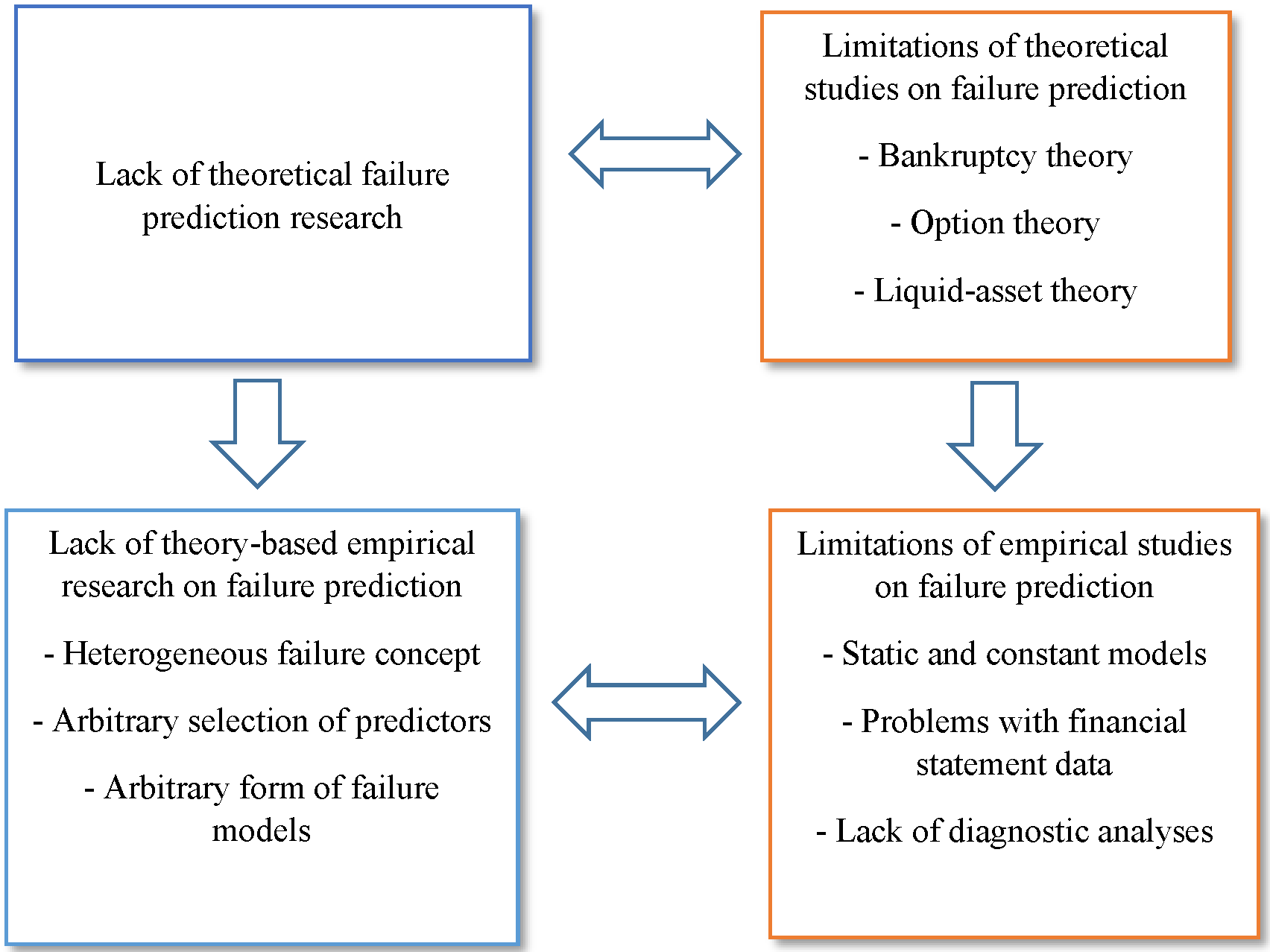
Figure 1 presents the framework of the limitations on financial failure research. The figure emphasizes the lack of strong theoretical grounds (top left corner of the graph) as the starting point of the scarce theory-based empirical research (down left corner of the graph). The insufficient theory and theory-based empirical research cause the specific limitations found in prior literature, both in theoretical and empirical studies (top and bottom right corners of the figure, respectively). Source: Own elaboration.
Figure 1 outlines that insufficient theoretical research is the starting point for the lack of theory-based empirical research. The right-hand side of Figure 1 illustrates that the specific limitations of theoretical and empirical studies, which are linked to the lack of theoretical and theory-based empirical research (left-hand side). These limitations have been extracted from the most cited and popular state-of-the-art reviews of financial failure prediction research in the ISI Web of Knowledge, summarized in Table 1.
Firstly, our review from prior state-of-the-art reviews, shown in Table 1, reveal that the main body of current research is mostly empirical, without any theoretical foundations (Alakaet al., 2016; Altman & Hotchkiss, 2006; Aziz & Dar, 2006; Balcaen & Ooghe, 2006; Jones, 1987; Jones & Hensher, 2004; Kirkos, 2015; Kücher et al., 2015; Laitinen & Kankaanpää, 1999; Lensberg et al., 2006; Peres & Antão, 2017; Scherger et al., 2019; Shi & Li, 2019; Zavgren, 1983). Secondly, empirical failure prediction research suffers from a lack of scientific dynamic analysis, being mainly focusing on traditional stable and static models based on cross-sectional financial statement data (Lukason et al., 2016). This feature of scientific research has led to severe difficulty and confusion in understanding the dynamic nature of the failure process, generalizing the estimated models, taking account of the unreliability of accounting information and applying failure models in smaller firms (Altman & Sabato, 2007; Balcaen & Ooghe, 2006; Ciampi, 2015; Cultrera & Brédart, 2016; Du Jardin, 2015; Lukason et al., 2016). Thirdly, failure prediction research lacks scientific analyses of reasons or factors leading to failure or non-failure (Appiah et al., 2015). Since there is no clear picture of what failure means in business, empirical failure prediction research is essentially concentrated on the rate of classification errors, while overlooking the reasons for misclassification explaining why some financially poor firms survive and some good firms fail (Scherger et al., 2019). An understanding of these reasons is, however, a prerequisite for developing more accurate models of failure. Current analyses of failure factors simply reflect expert systems based on the values of traditional financial ratios (Moynihan et al., 2006; Scherger et al., 2019; Sun et al., 2014). Thus, there is a need to consider "industrial dynamism, financial variables flaws and social factors which actually lead to the financial status of firms" (Alaka et al., 2016: p. 808).
Table 1. Main limitations mentioned in prior studies on financial failure prediction research
| Authors | Year | Journal | Title | Main limitations |
|---|---|---|---|---|
| Zavgren | 1983 | Journal of Accounting Literature | The prediction of corporate failure: the state of the art | -Absence of failure theory |
| Altman | 1984 | Journal of Banking and Finance | The success of business failure prediction models: an international survey | -Quality and reliability of companies’ information -Number of business failures, overall, for specific sector models |
| Dietrich | 1984 | Journal of Accounting Research | Discussion of methodological issues related to the estimation of financial distress prediction models | -Variable selection, estimation bias and statistical significance of coefficients -Sample selection bias (incomplete data and nonrandom sampling procedures) -Difficulties on interpreting results due to misunderstanding of methodology used |
| Zmijewski | 1984 | Journal of Accounting Research | Methodological issues related to the estimation of financial distress prediction models | -Sample selection bias (matched-pairs design used for collecting non-distressed sample) -Overestimation of distress firms sample frequency rates -Incomplete data of financially distressed firms |
| Barnes | 1987 | Journal of Business Finance & Accounting | The analysis and use of financial ratios: a review article | -Assumptions of multivariate normality in the distribution of sample groups -Equality of the group dispersion (variance and covariance) matrices -Determining the importance of individual variables and its information overlapping -Selection of prior probabilities and misclassification costs -Classification error rates -Inability of ratios to describe dynamic system of corporate collapse -Variables not stable over time but useful for predictive purposes |
| Keasey & Watson | 1991b | British Journal of Management | Financial distress prediction models: a review of their usefulness | -No explanatory theory of failure/distress -Selection of a reduced sample of ratios -MDA does not allow the significance of individual variables to be determined -Misclassification costs -Changes in legal criteria for failed firms -Different access of information depending on firm’s size (small or medium with large) due to publicly available data sets -Delays in the accounts’ submission -Random sample selection vs. non-random samples -Statistical overfitting -Ratios influenced by firms’ arbitrary accounting policies -Assumed temporal stability and predictive usefulness of macroeconomic conditions |
| Dimitras et al. | 1996 | European Journal of Operational Research | A survey of business failures with an emphasis on prediction methods and industrial applications | -Lack of a normal distribution fit to most financial ratios |
| Grace & Dugan | 2001 | Review of Quantitative Finance and Accounting | The limitations of bankruptcy prediction models: some cautions for the researcher | -Accuracy of the models declined when applied to time periods different from those used to develop the models -Model accuracy not sensitive to industry classification |
| Sharma | 2001 | Managerial Finance | The role of cash flow information in predicting corporate failure: the state of the literature | -Diversity of definitions for variables and ratios investigated related to cash flow -Too narrow concept of operating cash flow -Model validation and generalizability of the models derived -Multicollinearity between cash flow and accrual information -Different statistical techniques may produce different results |
| Aziz & Dar | 2006 | Corporate Governance | Predicting corporate bankruptcy: where we stand? | -Theoretical models often developed by employing available statistical techniques rather than directly on theoretical principles -Reliance on information from company accounts, and only marginal use of other information -Small sample size of listed firms and US data bias -Restrictive assumptions of multivariate discriminant analysis, logit and probit models -Lack of large time-series data sets required for cumulative sum procedures |
| Balcaen & Ooghe | 2006 | British Accounting Review | 35 years of studies on business failure: an overview of the classic statistical methodologies and their related problems | -Problems related to the classical paradigm (classical prediction models do not treat company failure as a process as dynamics; fixed score output of the classic statistical failure prediction models) |
| Perez | 2006 | Neural Computing And Applications | Artificial neural networks and bankruptcy forecasting: a state of the art | -The class of sound companies cannot be separated from the class of failing companies by a linear form, as both classes overlap |
| Nwogugu | 2007 | Applied Mathematics and Computation | Decision-making, risk and corporate governance: a critique of methodological issues in bankruptcy/recovery prediction models | -Usefulness and accuracy of financial ratio in bankruptcy modeling, particularly when combined with probability distributions that often do not reflect the underling processes. -Abnormal distribution of financial ratios -Ratios with static coefficients: inaccurate and do not capture the gradual and dynamic process -Annual data do not quickly reflect changes -Financial ratios do not capture all problems (competitive pressures, labor problems, or sudden product obsolescence) -Rank transformation for reducing the effects of non-normality of data -Autocorrelation, multi-collinearity of the variables and goodness-of-fit -Use of duration method (static models, sample selection bias, or small sample size) -Dependence on historical data -Seasonality and cyclicality of data not considered -Guarantees and post-default issues -Non-financial factors and cost of capital not considered in traditional models -Interpretation problems of some accounting ratios |
| Kumar & Ravi | 2007 | European Journal of Operational Research | Bankruptcy prediction in banks and firms via statistical and intelligent techniques – a review | -Statistical techniques in stand-alone mode not valid |
| Sun & Shenoy | 2007 | European Journal of Operational Research | Using Bayesian networks for bankruptcy prediction: some methodological issues | -Inappropriate selection of variables -Over-fitting problems (due to application of large number of features to limited data) |
| Ooghe & De Prijcker | 2008 | Management Decision | Failure processes and causes of company bankruptcy: a typology | -Different dimension of failure -Different influence of underlying nonfinancial factors -Management behaviours difficult to concrete |
| Bahrammirzaee | 2010 | Neural Computing & Applications | A comparative survey of artificial intelligence applications in finance: artificial neural networks, expert system and hybrid intelligent systems | -Complex non-linear systems difficult to comprehend -Problems of losing information, inappropriate data intervals and different conversion methods -Data distribution assumptions for traditional statistical methods |
| Divsalar et al. | 2011 | Expert Systems | Towards the prediction of business failure via computational intelligence techniques | -No rational model -Some artificial intelligent techniques do not provide any solutions to calculate the outcome using input values (no clear understanding of the nature of the derived relationships) -Missing information -Number of states for discretization of continuous random variables -Modeling continuous variables with probability density functions |
| Åstebro & Winter | 2012 | European Management Review | More than a dummy: the probability of failure, survival and acquisition of firms in financial distress | -Financial distress outcome is not a binary model |
| De Andrés et al. | 2012 | Knowledge-based Systems | Bankruptcy prediction models based on multinorm analysis: an alternative to accounting ratios | -Limitation of accounting ratios (strictly proportional and linear relationship between components) |
| Tascón & Castaño | 2012 | Spanish Accounting Review | Variables and models for the identification and prediction of business failure: revision of recent empirical research advances | -No linear relationship between explanatory variables and failure status -Validity of some models (due to requirement of normality in the distribution) -Dichotomous dependent variable (difficult to comply with two groups being identifiable, discrete and non-overlapping) -Limitations in all methodologies |
| Sun et al. | 2014 | Knowledge-based Systems | Predicting financial distress and corporate failure: a review from the state-of-the-art definitions, modeling, sampling, and featuring approaches | -No consensus about the concept of financial distress -Independent variables have a linear functional relationship with dependent variables -Neuronal networks are difficult to understand (complex network structure is a black-box) -Rough set methodology has shortcomings of unfixed structure and poor universality -Balanced versus imbalanced sampling -Unclear division between training and testing sampling -Cross-industry versus single industry sampling |
| Appiah et al. | 2015 | International Journal of Law and Management | Predicting corporate failure: a systematic literature review of methodological issues | -Arbitrarily defining the term corporate failure -No clear reasoning why firms failed -Lack of any real theory related to the use of financial ratios -Ad hoc selection of variables -Limitations of accounting information due to the availability of SME information and manipulation of accounting measures -Overlooked non-financial information -Overlooking the time dimension in relation to corporate failure (mostly one-year data) -Arbitrarily matching techniques |
| Kirkos | 2015 | Artificial Intelligence Review | Assessing methodologies for intelligent bankruptcy prediction | -Lack of any widely accepted theory of failure -According to theory, the data set size is related to the ‘variance’ problem -Different context of crisis era -The interpretation of the model for the extraction of domain knowledge is significantly wide -No validation procedure -Influence of data sets on models’ performance -Inclusion of financial or non-financial companies in data sets -Different timeline of data (two or more years prior to actual bankruptcy) -Difficulties in estimating the ability to predict each class value (bankrupt vs. non-bankrupt) -Feature selection problems |
| Kücher et al. | 2015 | Journal of International Business Studies | The intellectual foundations of business failure: a co-citation analysis | -No clear foundation or structured insight -Difficulty in determining the most accurate predictor (some focused on processes and consequences, while others based on distress ex ante) |
| Alaka et al. | 2016 | Construction Management and Economics | Methodological approach of construction business failure prediction studies: a review | -No paradigm for prediction models commonly accepted (main determinant should be research questions concerned about practical consequences) -One theory might be unsuitable for answering all types of research questions (multiple realities) -Usage of skewed data (equal data dispersion is vital - data balancing method should be used) -Model validation is necessary (using a separate sample) -Error costs should be considered for robust models -Variable selection (combination of industries’ dynamism, financial variables flaws and social variables for more rigorous and robust models) |
| Altman et al. | 2017 | Journal of International Financial Management & Accounting | Financial distress prediction in an international context: a review and empirical analysis of Altman’s Z‐score model | -Obsolescence of Z-score coefficients -MDA (assumptions of multinormality, homoscedasticity, and linearity) -Financial ratios affected by the macroeconomic environment -Limitations of the Z-score model (lack of consideration about the specific stage of a firm’s cycle, size, age, industry effect and country-specific differences) |
| Alaka et al. | 2018 | Expert Systems with Applications | Systematic review of bankruptcy prediction models: towards a framework for tool selection | -Ungeneralizable results (due to inappropriate application of traditional models) -Absence of formal theory -Improper uses of artificial intelligence tools without considering its limitations -Criteria required depending on model’s intention (accuracy, result transparency, non-deterministic, sample size, data dispersion, variable selection, multicollinearity, variable types, variable relationship, assumptions imposed by tools, sample specificity, updatability and integration capability) |
| Agarwal & Patni | 2019a | Journal of Commerce and Accounting Research | Applicability of Altman Z-score in bankruptcy prediction of BSE PSUs | -Many different definitions of bankruptcy -No guide to determine when bankruptcy occurs (takes place at any stage of an entity’s life cycle) -Bankruptcy risk predictions significantly differ due to different measurements and models |
| Farooq & Qamar | 2019 | Journal of Forecasting | Predicting multistage financial distress: reflections on sampling, feature and model selection criteria | -Country specific bankruptcy laws, accounting standards, and economic environments |
| Scherger et al. | 2019 | International Journal of Technology, Policy and Management | A systematic overview of the prediction of business failure | -Phenomenon full of subjectivity and uncertainty -Causes of failure not found (could be related to internal and external factors of companies’ organization) -Quantitative indicators (accounting and macroeconomic) mostly applied to distinguish between healthy and unhealthy firms -Too simple modeling (more sophisticated parametric and non-parametric techniques recommended) |
| Shi & Li | 2019 | Intangible capital | An overview of bankruptcy prediction models for corporate firms: a systematic literature review | -No commonly accepted bankruptcy prediction theory -Different theories all based on empirical techniques: rough set theory, case-based reasoning methodology or statistical learning theory -Lack of co-authorship (influential researchers have hardly worked together in the last five decades) |
| Kim et al. | 2020 | Sustainability | Corporate default predictions using machine learning: literature review | -Not a static issue (multi-period model in which future outcomes affected by past decisions) |
| Veganzones & Severin | 2021 | European Business Review | Corporate failure prediction models in the twenty-first century: a review | -No universal accepted definition -Multiple conceptualizations from many perspectives (e.g. juridical, economic, financial, econometric) -Heterogenous data (own corporate failure and accounting rules in every country) -Random selection from the population -Overrepresentation of failed firms relative to real-world populations -Limitations of financial ratios (market data, non-financial variables, variation of financial ratios or/and economic variables to be used as well) -Incorrect evaluation metrics -Impossibility to design unique prediction rule for its practical application -Lack of accessibility to firms’ information -Possible manipulation of financial information (earnings management) -Lack of complementary variables robustness -Large marginal cost of collecting complementary variables (compared to the increase of model accuracy) -Generally accepted theory not yet been proposed |
Table 1 summarizes, in chronological order, the most cited literature reviews in the ISI Web of Knowledge that mention limitations of the failure prediction research area. For every reference, Table 1 shows authors, year of publication, journal, title and theoretical and empirical limitations raise
In summary, the weaknesses in current failure research are a consequence of the fragmented scientific foundations created for failure analysis. As failure prediction research lacks a unique scientific theory, it is strongly focused on empirical, static models based on traditional financial ratios without any diagnostic analyses of the reasons for misclassification (Scherger et al., 2019). These empirical weaknesses can only be resolved when based on strong theoretical research. Thus, the development of the theoretical foundations for failure prediction should be the first priority in future research in this field. We suggest that these weaknesses can be eliminated only by strong theoretical scientific research on the failure phenomenon (what), failure reasons (why), and failure process (how) and, in addition, by empirical scientific research based on this theoretical framework.
We hope that this review will help future researchers to develop new groundbreaking innovative scientific approaches which are urgently needed. In the following sections, we analyse in detail the consequences of the lack of failure theory (Section 2) based on the evidence found in our review of research, the limitations of theoretical approaches (Section 3), and the empirical limitations on failure studies (Section 4). The discussion of these limitations is not restricted to the studies mentioned in Table 1, but also covers a wider range of references to facilitate a generalization of the findings. The conclusions and implications of our review are displayed in Section 5.
2. Consequences of the lack of theory
Reasoning from observations has been important to scientific practice at least since the time of Aristotle. Then, according to the Stanford Encyclopedia of Phylosophy (2017), logical empiricists transformed philosophical thinking in science in two ways: (1) the distinction between observing and experimenting and, (2) the assumption that a scientific theory is a system of sentences or sentence-like structures (propositions, statements, claims, and so on) to be tested. In this source, the idea that theories are said to save observable phenomena if they satisfactorily predict, describe, or systematize them is also cited. Consequently, failure prediction theoretical grounds should assist empirical models in this research area to achieve an accuracy of 100%. In this section, we reveal the consequences of the lack of a unique and commonly accepted scientific theory in failure prediction research.
2.1. Heterogeneous failure concept
There is a lack of theoretical research in failure prediction, firstly because the concept of failure is arbitrary and heterogeneous (Agarwal & Patni, 2019a; Appiah et al., 2015; Balcaen & Ooghe, 2006; Karels & Prakash, 1987; Keasey & Watson, 1991a; Sun et al., 2014). As per Kücher et al. (2015), the domain of bankruptcy prediction has no clear foundation or structured insight. The traditional concept used in many studies is a juridical definition of bankruptcy (or liquidation) which refers to a strong (severe) form of distress (Altman, 1968). To go bankrupt or not is less subjective than other proxies of failure concepts and easy to define, although it depends on the legal criteria used by each national corporate bankruptcy law (Kücher et al., 2015). Thus, according to prior research, there is an impact of the role of law enforcement on the concept of failure (Boughanmi & Nigam, 2017; Farooq & Qamar, 2019; La Porta et al., 1998; 2013; Veganzones & Severin, 2021). Davydenko & Franks (2008) suggest for similar firms filing for bankruptcy in different countries, we could expect different outcomes for creditors depending on the level of creditor protection provided by the bankruptcy code.1 Moreover, legal regulations are subject to changes that could alter the failure concept considered in models based upon data from earlier time periods (Keasey & Watson, 1991a; Laitinen & Suvas, 2013).
However, on the other extreme, failure models have been applied to predict payment delays referring to a very mild (less severe) form of distress (Wilson et al., 2000). For example, according to Basel II, the definition of financial distress used is 90 days overdue on credit agreement payments, and this is the best operational definition for major lenders (Altman et al., 2010). Other less severe criteria applied are a cut in dividends or the reporting of losses, profits below a forecast, capital evolution approaching zero (Appiah et al., 2015), or when a company's stock price is less than 10 cents in the case of dotcoms (Bose, 2006).
Nevertheless, other studies apply many criteria for distress in the same sample. For example, Agarwal & Taffler (2008) defined failure as entry into administration, receivership, or voluntary liquidation procedures, while Beaver (1966) considered a firm as failed when any of the following events occurs: bankruptcy, bond default, an overdrawn bank account, or non-payment of a preferred stock dividend. Sun et al. (2011) proposed the concept of relative financial distress when there is a relative deterioration in the financial situation for a certain enterprise related to the process of its life cycle.
It is obvious that severe forms of distress are easier to predict than less severe ones. In addition, different distress concepts require different models. In general, event-specific models may be of more relevance to users than a general distress model, based on multiple criteria for distress (Lau, 1987). In fact, the arbitrary definition of distress may have serious consequences for the resulting failure prediction model (Balcaen & Ooghe, 2006: pp. 72-73). Thus, rigorous theoretical analysis is warranted to conceptualize financial failure. The extant literature considers a single criterion of financial distress (yes or no) rather than its intensity (Åstebro & Winter, 2012; Scherger et al., 2015). In future studies, researchers could explore a metric that can better classify failed companies into several degrees of seriousness, such as mild, intermediate, and seriously (permanently) failed (as does Back, 2005). The current models give a score that can be used to approximate the likelihood of a failure, such as a bankruptcy situation. If the score is low, it can be concluded that the likelihood of bankruptcy is low, etc. However, even if the bankruptcy score is low, there may be a very high likelihood that the firm gets, for example, a serious payment default. The current models assume that the failure concept is homogenous, and the score monotonically measures the risk of failure, although there may be different failure phenomena in the sample that do not follow the scale of the score.
An empirical issue derives directly from the heterogeneous failure concept: the selection of non-failing control firms. When a sample of firms conforming to the selected failure concept is obtained, a sample of non-failed firms should be formed to discriminate between failed and non-failed firms (Keasey & Watson, 1991a). Since the failure concept is arbitrary, it is difficult to assess whether a firm fulfils the criteria for the non-failing firms or not. For example, some firms may suffer from payment defaults without being bankruptcy firms. Others may be technically failed or suffer from serious losses, but they do not go bankrupt. When the theory gives a non-arbitrary definition of failure phenomenon, the selection of non-failing firms can be accurately made from the population of firms that do not fulfil this definition. At this stage, it should be confirmed that the selected non-failed firms do not fulfill the criteria set for the failure to avoid inconsistency. There are several ways for sampling which may have affected the diversity of failure models and reported prediction abilities. Failure researchers can choose between the rest of the entire non-filled sample (e.g., Altman et al., 2017; García Lara et al., 2009; Laitinen & Suvas, 2016a, 2016b) or a control sample (e.g., Rose et al., 1982). Many prior studies follow the classical random sampling design (Jones & Hensher, 2004; Kim & Kang, 2010), although the control sample process is more often used. However, the procedure to obtain the control sample (i.e., by hand, randomly, or using the propensity score matching) and the characteristics selected for the matching (i.e., size, sector, and year) could also generate a bias problem (Åstebro & Winter, 2012). Indeed, Morris (1997) posits that the problem of sampling bias offers an explanation as to why the real market does not seem to behave in the way expected by the theory (Appiah et al., 2015). However, the paired-sample design helps in providing control over factors that otherwise might blur the relationship between predictors and failure (Beaver, 1966).
2.2. Arbitrary selection of predictors
Another direct consequence of the lack of a commonly accepted failure theory is the selection of dimensions or predictors for modeling, which are mainly chosen based on empirical grounds. This leads to the situation where the selection is sample-specific and the resulting model is also specific to that sample (Zavgren, 1983). Karels & Prakash (1987: p. 578) present a table of financial ratios employed by prior empirical studies of distress. This table shows a diverse selection, which is apparent given the limited normative basis, although there is no uniformity in terms of variable selection (Appiah et al., 2015; Taffler, 1983). The wide variety of ratios is underlined in a review paper by Bellovary et al. (2007), who report that a total of 752 different predictors have been used in failure studies. Of these variables, 674 are used in only one or two studies.
Typically, the predictors are chosen in two vague stages (Balcaen & Ooghe, 2006: pp. 79-81): initial set and final set. For example, Altman (1968) had 22 potentially useful ratios compiled for evaluation (initial set). Five of these ratios were selected as performing best when taken together in the prediction model (final set). The initial set usually consists of ratios from every main category, such as liquidity, profitability, debt, operating performance, cash flow, and market price ratios (if the firms are publicly traded). Sun et al. (2014) reviewed in detail the featured selection process, from qualitative to quantitative, and concluded that the former is subjective while the latter could be hard to explain or understand. Jones (2017, p. 1366) used the gradient boosting model to order the most accurate variables as predictors from the best to the worst based on their overall predictive power and found that non-traditional variables, as CEO compensation and accounting variables, are among the strongest predictors. However, some variables are available just for listed firms, such as CEO compensation. Thus, the variable selection is another challenge for failure prediction research, although a mix of techniques could be a good approach for selecting variables (Xu et al., 2014), as the ensemble of self-organizing neural networks (Du Jardin, 2021a; 2021b). This line of forecasting failure performs better than other models although it is a black box with a mode of operation that is totally unknown (Du Jardin, 2021b: p. 27) and difficult to comprehend (Bahrammirzaee, 2010).
The final set of predictors selection is dependent on the distress definition, the final selection method employed, and the time horizon for prediction. In typical distress models, liquidity, debt, and cash-flow ratios are represented (Karels & Prakash, 1987: p. 578). Profitability, however, is sometimes revealed to have a lower significance, especially in the short run (Altman et al., 2017). Financial ratios are often strongly correlated such that they include overlapping information, thereby making the final choice arbitrary. Given the lack of theoretical analysis, practically all estimated models are based on different predictors (Bellovary et al., 2007). As a consequence, statistical overfitting often occurs (Keasey & Watson, 1991a: p. 95). It is not possible to compare the performance of models or make any useful comparison between different types of firms (different sizes, industries, age, countries) or generalize models (Sun et al., 2014). For instance, regarding age, the reasons for corporate demise differ depending on firm age and life cycle stage. Young and adolescent firms predominantly fail due to internal shortcomings, whereas mature small and medium-sized enterprises (SMEs) struggle more with increased competition and economic slowdowns (Kücher et al., 2018). In summary, the lack of theoretical analysis makes the models data-specific, leaving the area of failure research fragmented.
The set of predictors can also vary to a significant degree due to the different time horizons chosen for the prediction. This is because the significance of potential predictors strongly varies with respect to the years to failure (Zavgren & Friedman, 1988). Pompe & Bilderbeek (2005) noted that models generated from the final annual report, published before bankruptcy, were less successful in the timely prediction of failure, while economic decline coincided with a deterioration in the model performance. In short-term models (one year prior to failure), the choice of predictors is arbitrary on empirical grounds, since almost all financial ratios unanimously indicate poor performance for failing firms. Indeed, traditional models with any predictors achieve good short-term performance, which, however, often strongly deteriorates when the horizon exceeds one year. It is evident that more theoretical research is needed to describe the longer-term behavioural process of firms before failure (Aziz & Dar, 2006; Laitinen, 1991). Empirically, Du Jardin (2015) used terminal failure processes in prediction and achieved higher accuracy with a three-year horizon than that achieved with the traditional one-year horizon model.
Another issue related to the variables concerns the basic inputs of the models. Normally, accounting variables have been mostly used. However, due to the fact that financial ratios are influenced by arbitrary firms' accounting policies (Keasey & Watson, 1991b), differences in accounting practices jeopardize the ability of predictors to reflect these characteristics identically in all countries (Laitinen & Suvas, 2013). Moreover, accounting measures are subject to manipulation, due to the accounting policies or estimations elected in respect of, for example, depreciation, inventory valuation, and revenue recognition (Rosner, 2003). Thus, information from financial statements may not necessarily be true and fair (Appiah et al., 2015). Indeed, the behaviour of managers in financial distress situations could question the reliability of financial statements and increase accounting manipulation (Campa & Camacho-Miñano, 2014, 2015) and even corporate governance indicators could improve failure prediction models (Kallunki & Pyykkö, 2013; Liang et al., 2020).
For these reasons, several studies have included variables other than accrual-based accounting ratios such as cash-flow variables (i.e., Aziz et al., 1988; Aziz & Lawson, 1989; Casey & Bartczak, 1984, 1985; Gombola & Ketz, 1983; Laitinen, 1994; Sharma, 2001), auditing data (i.e., Keasey & Watson, 1987; Muñoz-Izquierdo et al., 2019a, 2019b), macroeconomic conditions (i.e., Altman, 1983; Hernández Tinoco & Wilson, 2013), market data (i.e., Hillegeist et al., 2004; Marais et al., 1984) or non-financial variables (i.e., Altman et al., 2010; Appiah & Chizema, 2015; Back, 2005; Fich & Slezak, 2008; Iwanicz-Drozdowska et al., 2016; Keasey & Watson, 1987; Laitinen, 1999; Lussier, 1995). However, later research has still shown the validity of accounting ratios for predicting financial failure (Altman et al., 2017).
2.3. Arbitrary form of failure models
Traditional models often use a pre-assumed form of a function of original financial variables in distress prediction. This form is typically linear which may lead to severe specification errors (Balcaen & Ooghe, 2006: pp. 81-82; De Andrés et al., 2012). For example, discriminant analysis and linear regression analysis employ a linear function to the original variables. Logistic regression analysis applies a logistic function to the linear logit of the variables and it has been recently validated as an efficient methodology to predict bankruptcy up to 10 years before the event (Altman et al., 2020). Proportional hazard survival analysis applies an exponential function to the linear log-relative hazard, whereas neural network analysis might implement complicated non-linear functions to the linear combinations of original or standardized input variables. The linear form is especially problematic because it assumes a proportional compensation between the predictors.
The functional form used in prediction models is not justified on theoretical grounds but typically draws only on the assumptions of the methods used. In the linear form, the marginal effects of predictors are constant and a decrease in a predictor can be fully compensated by an increase in another. However, this kind of full compensation is not a justified assumption in distress prediction (Laitinen & Laitinen, 2000). In severe financial distress, extremely low liquidity, for example, cannot be fully compensated by profitability or leverage. Without rigorous theoretical analysis, it is not possible to understand how different financial dimensions factually interact with each other and how the model should be specified to determine the appropriate compensation.
The lack of theoretical analysis is sometimes compensated by using data mining techniques (Balcaen & Ooghe, 2006). For example, Cho et al. (2009) developed an integrated model combining statistical and artificial intelligence (AI) techniques for bankruptcy prediction. Since then, there has been a growing trend in the literature on bankruptcy prediction models that apply AI techniques, as advocated by Divsalar et al. (2011) and Alaka et al. (2018). AI tools are computer-based techniques, with artificial neural networks being the most popular for bankruptcy prediction (Aziz & Dar, 2006; Tseng & Hu, 2010).
Other AI tools have been applied to the bankruptcy prediction research domain, such as support vector machines, rough sets, case-based reasoning, decision trees, and genetic algorithms (Alaka et al., 2018; Aziz & Dar, 2006; Min et al., 2006). However, there is still no consensus about which techniques are more accurate for predictive power (Alaka et al., 2018; Du Jardin, 2010, 2015; Kim & Kang, 2010; Scherger et al., 2019; Tseng & Hu, 2010). This conclusion is not surprising given the many different ways each technique can be parametrized and the specifics of the problem addressed. In a nutshell, there is no evidence that one data mining technique outperforms the others under all circumstances (Amani & Fadlalla, 2017: p. 44). This kind of situation is expected in the case of purely empirical research. More theoretical work on failure is warranted in order to examine data mining processes.
Alaka et al. (2018) carried out another systematic literature review using Web of Science, Business Source Complete and Engineering Village. They found 49 papers from 2010 to 2015 on bankruptcy prediction models, pointing out that there is an absence of a formal theory for the selection of techniques to anticipate corporate failure. According to this review, techniques to develop tools for predictive models are used with the wrong data conditions or for the wrong situation, while there seems to be no single statistical or AI tool that is, on its own, predominantly more accurate than others. Thus, they suggested a framework of guidelines for the selection of tools that best fit different bankruptcy situations.
3. Limitations of theoretical failure approaches
Thus, failure research is suffering from a lack of theoretical foundations. However, there are a few (limited) theoretical approaches that have implications for scientific empirical research. In this review, these approaches are classified into the following categories: bankruptcy theory, option theory, and liquid-asset (cash-flow) theory. In this review, coalition behaviour theories are not considered, although they may have implications for the relevance of financial ratios in bankruptcy decisions (Routledge & Gadenne, 2000)2. Bulow & Shoven (1978) focused on the conflicts of interest among various claimants to the assets and income flows of the firm (stockholders, bondholders, and bank lenders). White (1981, 1983, 1989) extended the Bulow & Shoven theory to firms' decision-making between the liquidation and the reorganization stages under bankruptcy law. These approaches could illustrate the relevance of some financial ratios to a distressing situation where a bankruptcy decision is considered.
3.1. Bankruptcy theory
First, bankruptcy theory can be used to recommend how predictors should be selected and modeled to be theoretically justified (Scott, 1981). Wilcox (1971, 1973, 1976) and Santomero & Vinso (1977) developed a stochastic bankruptcy theory based on the gambler's ruin model.
Scott (1981) further developed this kind of theory and showed that the probability of failure is an explicit function of the expected value and the standard deviation in the change in retained earnings (net income minus dividends), as well as the current market value of equity, all divided by total assets. Thus, this approach suggests that profitability, together with its volatility and the equity ratio, are important predictors of bankruptcy (Laitinen & Suvas, 2016a, 2016b). The functional form between the profitability ratio and the equity ratio is linear but their relationship to volatility is proportional.
Scott showed that, in this form, the probability of failure has obvious similarities with the empirical ZETA model proposed by Altman et al. (1977). Both models contain stock variables that reflect the financial position at a point in time and flow variables that involve estimates of future cash flow distribution. Scott also expanded the basic model and theoretically demonstrated that the size (total assets in ZETA) and the liquidity of the firm (current ratio in ZETA) can also affect bankruptcy probability. He further showed that his theory of bankruptcy fits the data better than earlier empirical models. Scott (1981: p. 342) concluded that bankruptcy prediction is both empirically feasible and theoretically explainable while believing that it may be possible to improve the predictive accuracy of prediction models using variables (and functional forms) suggested by bankruptcy theory. However, his theoretical model is still in a preliminary state: it is focused on the bankruptcy concept and only gives limited support to empirical bankruptcy research on public firms.
3.2. Option theory
The probability of bankruptcy can also be described by option theory (Agarwal & Taffler, 2008; Campbell et al., 2008; Charitou et al., 2013; Giesecke & Goldberg, 2004; Vassalou & Xing, 2004). In this framework, the prediction of bankruptcy is defined as the probability that the call option will expire worthlessly, or that the value of assets is less than the face value of the liabilities at the end of the holding period. Thus, the probability of bankruptcy depends on the value of assets, the face value of debt, the expected return of the firm, the rate of dividends, asset volatility and the time to expire (McDonald, 2002).
In this framework, the functional form between the variables is non-linear and has similarities with the model suggested by Scott (1981). Probability is a function of the distance between the current value of assets and the face value of liabilities, adjusted for the expected growth in asset values relative to asset volatility. Hillegeist et al. (2004) compared the bankruptcy risk information assessed by this kind of option-pricing model (market-value based) with the empirical Z-score by Altman (1968) and the empirical O-score by Ohlson (1980). The tests showed that the option-pricing model provides significantly more information than either of the scores (accounting-based measures).
Hillegeist et al. (2004) suggested that researchers should use the option-pricing model instead of traditional accounting-based measures as a proxy for the probability of bankruptcy. This model is based on market prices and can be estimated at any point in time for any publicly traded firm regardless of the time period and industry. The model can be modified to compute probability over any time horizon by changing the time parameter, while, in accounting-based models, the estimates are specific to the predictive horizon. However, option theory is limited in the same way as bankruptcy theory, being strongly focused on the bankruptcy concept and the sufficiency of asset values to cover the face value of debt in public firms.
3.3. Liquid-asset theory
The probability of failure can also be theoretically outlined by cash-flow concepts. This kind of cash-flow (liquid-asset) framework for failure prediction was presented by Beaver (1966). His simple model is based on the technical insolvency concept originally presented by Walter (1957). Technical insolvency exists when a firm cannot meet its current financial obligations, signifying a lack of liquidity (Altman & Hotchkiss, 2006: p. 5). Thus, this theory is not based on the bankruptcy concept but emphasizes a liquidity crisis. It shows that net cash flows relative to current liabilities should be the primary criterion used to describe technical insolvency. Technical insolvency may be a temporary condition reflecting liquidity problems, although it could represent an immediate cause of legal bankruptcy as well.
Technical solvency relates to the ability of a given business unit to meet its currently maturing obligations. It is a special subclass of solvency within boundaries defined by the time interval, say, 12 months, under consideration (Walter, 1957: p. 30). In this theory, the firm is viewed as a reservoir of liquid assets, which is supplied by inflows and drained by outflows (Beaver, 1966: p. 80). The reservoir serves as a cushion or buffer against variations inflows. Solvency can be defined in terms of the probability that the reservoir will be exhausted, revealing at which point the firm will be unable to pay its obligations as they mature (failure). This approach, in its present form, is not based on any mathematical framework.
Liquid-asset theory is based on four factors: the size of the reservoir, the net liquid-asset flow from operations, the debt, and the fund expenditures for operations (the number of liquid assets drained from the reservoir by operating expenses). Thus, ceteris paribus, the larger the probability of failure, the smaller the reservoir, and the smaller the net liquid-asset (cash) flow, the larger the debt and the larger the fund expenditures for operations. These propositions form predictions for the mean of six ratios: cash flow to total debt, net income to total assets, total debt to total assets, working capital to total assets, the current ratio, and the no-credit interval (defensive assets minus current liabilities to fund expenditures for operations). Beaver (1966) tested the predictive ability of these ratios to anticipate failure (75% of the failed firms consisted of bankrupt firms). The cash flow-to-total debt ratio was the most accurate univariate predictor and the net income-to-total assets ratio was the second-best predictor. The total debt-to-total assets ratio was the next most precise predictor, with the three liquid-asset ratios performing least well (Beaver, 1966: p. 86).
Liquid-asset theory has similarities with the cash-flow theory based on the identity defined by Lawson (Aziz et al., 1988; Aziz & Lawson, 1989). This theory is a simple decomposition of the cash-flow identity into several parts. These parts are used to form cash-flow ratios when scaled by the book value of the firm. In bankruptcy prediction, operating cash flows, taxes, and interest payments minus the change in debt were the most significant predictors. When compared with the ZETA model (Altman et al., 1977) and the Z-score model (Altman, 1968), the overall accuracy of the cash flow model was approximately equal (Aziz et al., 1988: p. 435). Casey & Bartczak (1985), Gentry et al. (1985), and Laitinen (1994) reported similar or worse results concerning the accuracy of cash-flow measures. Thus, liquid-asset theory and cash-flow models only provide limited, if any, contributions to traditional accrual-based financial failure models. However, since failure is an empirical event with characteristics of both bankruptcy and liquidity crisis, future researchers should seek to develop a theoretical framework by combining these two approaches (as does Laitinen, 1995).
4. Limitations of empirical failure studies
The lack of theoretical foundations for failure research has led to empirical studies that are fragmented, leading to an absence of any clear focus or consistency. Empirical failure studies try to identify efficient models in order to predict the complex and theoretically under-explained event of failure using an ad hoc variety of predictors, usually financial and/or non-financial variables from different databases. However, these empirical studies suffer from limitations concerning modeling, data, and interpretation. In the next section, these limitations are briefly discussed.
4.1. Static and steady modeling
Classic statistical failure modeling, based on the supervised classification of firms, assumes a constant (master) model for the sample. It requires the relationship between variables to be stable over time while remaining unchanged in future samples. Thus, it assumes that the distributions of the model variables do not change over time, implying stationarity, i.e., a stable relationship between the independent variables and the dependent variable (Balcaen & Ooghe, 2006; Edmister, 1972; Jones, 1987; Zavgren, 1983). However, there is strong evidence of data instability and non-stationarity in financial statement data, resulting, for example, from changes in economic cycles, competition, interest rates, inflation, strategies, and technologies. This instability is more serious for small and failing firms. Thus, classic failure models dangerously suffer from stationarity problems.
Non-stationarity and data instability may have severe consequences for classic statistical failure prediction models (Balcaen & Ooghe, 2006). In addition, classic models assume that the unified master model is useful when analysing all types of failing and non-failing firms (small, large, and different industries, different ages). However, this assumption does not hold in reality. For example, small firms are not identical to small versions of large firms. Instead, they have specific characteristics which cannot be included in failure models estimated for large firms (Altman & Sabato, 2007; Keasey & Watson, 1987; Kücher et al., 2018; Storey et al., 2016).
Static classic statistical failure prediction models ignore the fact that companies change over time, which leads to serious limitations (Balcaen & Ooghe, 2006). The estimation of failure models is usually based on one single observation (annual financial statement information from one year) for each firm in the sample. This implicitly assumes that annual financial statements are independent and rely on repeated measurements, which do not hold. Thus, static failure models do not pay attention to the time series of failing firms. Consecutive financial statements can lead to conflicting predictions of failure, resulting in signals of inconsistency. This means that classic failure models do not regard failure as a process, which can derive from several problems with the application of the models. They do not consider information about the dynamics of the predicting process but assume that failure is a steady-state (Laitinen, 1993; Laitinen & Kankaanpää, 1999; Luoma & Laitinen, 1991). Thus, the underlying failure process is assumed to be stable over time, while no phases are distinguished (Kim et al., 2020; Nwogugu, 2007).
However, this strongly contrasts with reality. Failure is not a sudden and unexpected event (Luoma & Laitinen, 1991). Instead, failure is the result of a process consisting of several phases, each characterized by a specific behaviour of certainty. Moreover, classic statistical models do not consider possible differences in failure paths. They assume that all companies follow a uniform failure process (Balcaen & Ooghe, 2006). However, in practice, there is a wide variety of failure paths (Laitinen, 1991). For example, the failure processes of small firms are different from those of large corporations (Lukason, 2016; Ooghe & De Prijcker, 2008).
Laitinen (1991) found three different failure processes for SMEs through factor analysis: chronic failure firm, revenue financing failure firm, and acute failure firm. For almost half of failed small companies, the process was both short and quick, such that an acute failure type was dominant (Laitinen, 1991). This kind is difficult to predict using traditional models in the case of large firms. In the future, more attention should be paid to the failure process in prediction models in order to increase accuracy across a longer horizon (Aziz & Dar, 2006; Du Jardin, 2015).
4.2. Problems with financial statement data
Classic cross-sectional failure models only use annual account information in the form of financial ratios because these ratios are considered hard and objective measures and they are based on the publicly available information (Altman et al., 2017; Dirickx & Van Landeghem, 1994; Laitinen, 1992; Micha, 1984). However, financial ratios are subject to many criticisms, while annual account-based models have proven to experience some serious drawbacks (De Andrés et al., 2012; Veganzones & Severin, 2021). For example, failure models based on financial ratios suffer from the occurrence of extreme ratio values (Balcaen & Ooghe, 2006). Therefore, models may be strongly biased or contaminated (Moses & Liao, 1987) and show biased coefficients for the ratios involved. In addition, failure models implicitly assume that annual accounts give a fair and true view of the financial situation, which does not hold. Failing firms especially have incentives to manipulate or manage their annual account figures (Burgstahler & Dichev, 1997; Campa & Camacho-Miñano, 2014, 2015; DeFond & Jiambalvo, 1994; Ooghe et al., 1995; Rosner, 2003; Sweeney, 1994).
Typically, failing firms use earnings management to adjust their earnings upwards, especially when the moment of failure is very near (Campa & Camacho-Miñano, 2014). In earnings management, accruals (the difference between accruals and cash flows) are the main method to reflect the quality of published financial figures (Barton, 2001; Subramanyam, 1996). In general, accruals create uncertainty in financial statement analysis, which may diminish the value of financial information. Moreover, annual financial information may be unreliable, especially in smaller firms, because of the lack of any internal and audit control system (Keasey & Watson, 1986, 1987). To avoid unreliability problems in terms of accruals, some failure studies have suggested using components of cash flow-based funds instead of accrual-based financial ratios in failure prediction modeling (Aziz & Lawson, 1989; Gentry et al., 1985, 1987).
Failure studies have also suggested the need to improve model performance when using integrated accrual cash-flow models, that is, by adding cash-flow ratios to models based on accrual-based financial ratios (Gentry et al., 1985; Gombola & Ketz, 1983). The results of studies using cash-flow ratios alone are not promising, but it may be beneficial to combine accrual-based and cash-based ratios in the same model. On the other hand, Sharma (2001) suggests that there are multicollinearity issues between cash flow data and accrual information. Thus far, the conclusion is that, due to the unreliability of annual account information, failure models based on financial ratios may be distorted and their practical usefulness limited. In other words, financial reporting qualities affect the informativeness of accounting numbers for bankruptcy prediction ability as empirically shown by Beaver et al. (2012).
Some forces fundamentally reshape the economic and business world in a way that diminishes the value of financial information when predicting the failure of a firm in general (Johanson et al., 2001). Nowadays, the only sustainable competitive advantage that can be truly achieved is based on intangible assets which cannot be identified on a conventional financial balance sheet. Hence, the balance sheet is highly limited in its ability to reflect the failure risk of firms in terms of emphasizing intangibles. The usefulness of such traditional financial information is questionable, especially in technology firms, which invest heavily in intangible assets, such as R&D, information technology, and human resources. Using Compustat firms, Lev & Zarowin (1999) showed that there was a weakening of returns-earnings, returns-cash flow, and price-earnings-book value relationships during the period 1978-1996. This weakening of relationships refers to a notable loss of value relevance concerning financial information. Lev & Zarowin (1999: p. 354) focused their analysis on intangible investments as a major explanation for the decline in information usefulness: We argue that it is in the accounting for intangibles that the present system fails most seriously to reflect enterprise value and performance, mainly due to the mismatching of costs with revenues. They also identified the increasing rate and impact of business change and the inadequate accounting treatment of change and its consequences as reasons for the usefulness decline. Thus, Lev & Zarowin (1999) completed the linkage between intangibles related to a business change and the loss of the value-based relevance of financial information. According to them, the social and economic consequences of the decline in the usefulness of financial information have not been examined sufficiently. If analysts can obtain the information that is increasingly missing from financial ratios by using new innovative methods, then the social consequences of a decline in accounting usefulness may not be so serious. Thus, there is an urgent need for methods to model financial statement information in new ways in order to gain in relevance.
The problems with the data are even more serious in failure prediction studies which use financial statements from different countries (Altman et al., 2017; Laitinen & Lukason, 2014; Laitinen & Suvas, 2016a, 2016b). Therefore, researchers have developed country-specific prediction models for developed countries, such as the US (Altman, 1968; Altman & Sabato, 2007; Altman et al., 2017, Zavgren, 1985; Zmijewski, 1984), the UK (Charitou et al., 2004; Taffler, 1982), Belgium (Cultrera & Brédart, 2016), Finland and Estonia (Laitinen & Lukason, 2014), Italy (Ciampi, 2015) or Spain (Camacho-Miñano et al., 2015; Muñoz-Izquierdo et al., 2020), as well as, more recently, for developing countries, such as Colombia (Altman et al., 2017), India (Agarwal & Patni, 2019b; Vel & Zala, 2019), Pakistan (Waqas & Md-Rus, 2018), or China, Malaysia and Thailand (Petpairote & Chancharat, 2016). Some popular failure prediction models have also been used widely in countries other than the country of origin (Altman & Narayanan, 1997; Altman & Hotchkiss, 2006: pp. 259-264; Bellovary et al., 2007).
However, the predictors and their importance considerably differ between country-specific models, making the application of a model to foreign firms questionable (Ooghe & Balcaen, 2007; Veganzones & Severin, 2021). In an international context, it is especially difficult to obtain comparable results and to derive generalizable conclusions. Typically, the estimators and the subsets of predictors differ transversely. While there are temporary inconsistencies materialized in adhocratic models for each time window, alongside there is a need to re-estimate models to maintain their predictive capacity (Jiménez Cardoso, 1996; Piñeiro-Sánchez et al., 2012). So far, the effects of international differences between countries on failure predictors have not been systematically analysed (Laitinen & Suvas, 2016a, 2016b). This sets a clear challenge for failure studies in the future.
4.3. Lack of diagnostic analyses
Traditional failure models give a fixed score as an output to reflect the failure risk of a firm. However, this score is difficult to interpret and contradicts generic intuition (Balcaen & Ooghe, 2006). A model score below a certain threshold highlights financial difficulties (indicating that the firm might fail), but it does not indicate whether a company will fail. Thus, failure models have a retrospective character. This means that failing and non-failing firms have dissimilar characteristics, not that the model variables have predictive power (Ooghe & Joos, 1990). Their retrospective character and the notion of resemblance lead to statistical failure prediction models having a descriptive or pattern recognition nature (Keasey & Watson, 1991a; Taffler, 1982, 1983).
Developed failure models should not be seen as prediction devices, but rather as communication devices that can explain the causes of failure (Kim et al., 2020). However, the communication of the results is difficult which calls for an expert system to support the interpretation. This expert system is a computer program that simulates the judgment and behaviour of a human or an organization with expert knowledge and experience in a particular field. Typically, such a system contains a knowledge base embodying accumulated experience and a set of rules (inference engine) for applying the knowledge base to each particular situation that is described to the program. Expert systems of this type have been incorporated into financial failure models (Barboza et al., 2017; Metaxiotis & Psarras, 2003; Moynihan et al., 2006; Muñoz-Izquierdo et al., 2019a, 2019b; Pavaloaia, 2009; Shin & Lee, 2002; Shiue et al., 2008; Zięba et al., 2016).
However, the crucial weakness in typical expert systems is that their interpretation rules make use of pattern recognition based on traditional financial ratios. Thus, the diagnosis is purely empirical and superficial, reflecting the weaknesses in empirical research. Failure studies lack theoretical research and, therefore, deep diagnostic systems with a theory-based inference engine. Such a system would not be descriptive but rather normative and causal, supporting not only failure analysis but also decision-making. It may serve as an efficient early warning system for a firm to avoid failure. The development of this kind of expert system is not possible without innovative theoretical research on the foundations of the failure process. Thus, future researchers are urged to develop, first of all, failure process theory and, secondly, expert systems based on this theory. Failure process theory should pay attention to the financial situation of the firm as well as the dynamics of its behaviour in a dynamic environment. That said, the problem regarding the lack of financial failure theory could be in line with Inanga and Schneider (2005: p. 227), who states that the central problem of accounting research is that there is no known theory to use as a reference for creating hypotheses or models to be empirically researched.
5. Conclusions, implications, and future research avenues
In this paper, we contribute to prior literature on the popular and highly studied topic of financial failure prediction by providing a review of the limitations of this research area. This is the first study that classifies and explores failure prediction boundaries and assesses these limits from both theoretical and empirical approaches.
From the theoretical approach, we explain that financial failure prediction research lacks a unique scientific theory, due to the inability of theoretical analysis to act properly in a situation where the target phenomenon (failure) cannot be described by one definite approach. Typically, the objective of failure prediction studies has been to increase the accuracy of prediction models making experiments with different statistical methods or new types of data (Scherger et al., 2019). Most contributions in the area are related to the development of more efficient statistical methods but not to the development of theoretical foundations of failure to increase understanding of the phenomenon (Appiah et al., 2015). To some degree, bankruptcy and option-theory models have helped model builders to develop models based on profitability, its volatility, and the leverage of the firm. In addition, the liquid-asset and cash flow theories have an increased understanding of the importance of liquidity as a determinant of failure. However, bankruptcy- and option-theory models are only useful for predicting bankruptcy, while cash-flow models are only appropriate for predicting liquidity distress. Thus, in summary, the most striking aspect of financial failure analysis is the lack of coherent theoretical grounds, which would be suitable for different types of failure and diverse firms with different types of information.
From the empirical point of view, due to the lack of solid theoretical scientific grounds, financial failure prediction research is strongly characterized by purely empirical studies (Alaka et al., 2018; Balcaen & Ooghe, 2006; Dimitras et al., 1996; Kirkos, 2015; Lensberg et al., 2006). This has made failure research highly fragmented without a clear focus. In empirical studies, a multitude of concepts has been used to represent failure, although their target phenomena are very different and would require a different theory to be applied. For example, payment default and bankruptcy are very different phenomena, since the former concept is based on liquidity and the latter concept on solidity. Therefore, one failure theory cannot explain both of them. Despite that, empirical research applies the same definition to both concepts. Apart from the unclear concept of failure, the deficient theoretical foundations of failure prediction have led to limited success in empirical work. First, all prediction models do not apply to every type of firm (such as small firms or privately held firms), nor are they sensitive to or dependent on the quality of data (for example, earnings, market value, or the mismatching of cash flows). In addition, they have led to unstable results (prediction accuracy is not consistent over time) and failed to significantly increase prediction accuracy. Indeed, they have sometimes produced even worse results than models built purely on empirical grounds (such as the stepwise model).
As a result of the evidence found in our literature review, some academic implications can be drawn. First, it seems that one financial failure theory might be unsuitable for answering all types of research questions as there may be multiple default realities depending on the period and the firms' specific characteristics. Therefore, we propose the application of a partial failure theory that is limited just to the (one) concept adopted in every study, which leads to a consistency between the theory and the empirical approach. In this sense, heterogeneity might not be considered a limitation of the research field and could thus be regarded as an opportunity to build a set of partial theories of the failure concept.
Second, these theories could not be very detailed and their development does not need to be mathematical. It can consist of a set of sentences that create a coherent framework for understanding the failure event and the dynamics of the failure process. One approach to constructing failure theory could be based on multiple case studies which explore social factors related to the failure. The reason for proposing case studies is to allow a comprehensive investigation of the failure phenomenon by investigating multiple failed and existing firms (Alaka et al., 2016). Additionally, Kücher et al. (2018) suggest that qualitative case studies, not quantitative analysis, may be more appropriate to examine the individual dynamics of roads to financial failure. Furthermore, those case studies could be complemented with unstructured interviews and/or focus on group discussions to generalize the results obtained.
Third, the big data era has recently transformed many traditional research problems (Demchenko et al., 2013). Researchers can build almost perfect models with machine learning techniques and with the analysis of high amounts of data. Thus, we suggest that a way to develop a commonly accepted financial failure explanatory theory could be based on the usage of big data. Finally, very influential researchers have hardly worked together on the topic in the last five decades (Shi & Li, 2019). We encourage co-authorship in this research area in order to overcome all the theoretical and practical limitations highlighted in this study
Lastly, practical implications are also derived from this study. First, as our findings indicate that there are future challenges to develop new theoretical scientific grounds of the failure phenomenon, this should increase firms' understanding of their financial failure processes and lead to generalizable models. These models appear to be useful for predicting purposes as well as diagnostically interpreting and communicating the distressing behavior of businesses. Second, when firms fail, terrible negative consequences appear, such as losses, unemployment, and recession. For managers and employees, knowing more about the reasons why their businesses fail could prevent or minimize these negative consequences. This review might represent a timely and relevant contribution because we provide new challenges on this topic with the hints of a new economic crisis due to Covid-19.